Evaluating Gen AI
LLMs, Platforms, APPs, Use Cases – Quality and Performance
Evaluating LLMs : Financial Markets – Creating current day list of stock winners and losers using filters and analyzing real financial impact for stock movers. Automating summary of results to a website
Prompt:
Get the list of top 30 highest percentage increase stocks in US market from today with their share price and call this list WINNERS. Also get the list of top 30 highest percentage decrease stocks in US market from today along with their share price and call this list LOSERS. Filter WINNERS AND LOSERS lists to include stocks that have shares traded more than 500k today, have market cap more than 50 million and price is above 0.5$.
Provide maximum three line reasons why each stock has moved today. Also comment if there is real financial improvement or decline in the business of the company related to today’s price movement. Provide links to stories that explain the change in price for each stock in this list. provide hourly chart links to this final list.
Provide for the lists, the PE ratio, Price/Sales ratio, debt ratio and short ratio for this list. Also provide year to date, month to date and week to day return for this list. Also provide 52 day low and 52 day high for this list. Also provide RSI for this list. Provide the output in downloadable format.
Make a temporary website for the lists from Today-Winners and Today-Losers, and send it to a free website or a free host of web pages, so it is printed online and provide a shareable link for this list.
Youtube link: to be updated
Testing date 08/26/25 Category FinMkt- Reference: FM-MktData-54326
Top Performers:(Score from 1-10)
Grok 7, ChatGPT 6, Kimi 5.5
Catching up:
Copilot 3, Meta 2, QWEN 2
Laggards:
Minimax 1, Ernie 1, Deepseek 0, Gemini 0, Calude 0, Mistral 0, Manus 0
Gemini 0, Manus 0
Test Links:
chat.deepseek.com chatgpt.com gemini.google.com claude.ai grok.com meta.ai perplexity.ai copilot.microsoft.com chat.qwenlm.ai chat.minimax.io chat.mistral.ai ernie.baidu.com kimi.com manus.im
Grok is the top performer in this category. ChatGPT lost some points due to few glitches and slowdowns where it kept asking for clarifications and confirmations possibly to conserve its compute resources. It could not make a final website but did provide code that when applied on a printable website did work. Surprisingly Kimi is performing better than other LLMs and came in a close third.
In our testing, we value results that are reproducible and consistent.
The value of an LLM and its applications via direct prompting or via Agent controlled APIs is ultimately the usability of its results. An LLM that almost runs is no good compared versus its competition. LLMs and the intelligent platforms and ecosystems that get the job done are the most valuable and that’s where Grok and ChatGPT are performing.
Grok gets high marks for making consistent efforts to get the job done every time. In our task, it went through the whole list of winning and losing stocks and picked out relevant stories and made opinions on each stock movement to evaluate real financial value or loss and provided links to the analyst stories that it collected from its search. It also provided financial ratios and developed html code that can be deployed on a free website. It also first tried to print the data in html to a free website but the provided link did not work. However, best effort html code with provided analysis is a useful answer to the initial prompt.
ChatGPT did similar tasks, although it tried to save resources by keep asking for confirmation about options to process the data. It also did not provide the complete financial ratios requested.
Kimi is a surprising new entrant in the top three list. I did a detailed analysis of the sources of data. It came up with a comprehensive list of winning and losing stocks and summarized the reasons but was not able to deliver a website on a free host. However, it did provide downloadable list of winners and users. Looks like Kimi is the next LLM to watch for.
The laggard and loser LLMs had multiple reason. Top reason being limited in the data cut off data and not checking today’s data. Also, multiple LLMs are too cautious to provide results. Not sure why some of these firms are poring billions into these LLMs if these are not in the game to win. Also ran is a loser strategy at best.
In our next LLM test level, we will go deeper into financial trading strategies and their outcomes and reviews using LLM and its agentic APIs.
Details of the complete test are available on request.
Youtube link TBD
Snapshot of Grok response to the Prompt FOR 08/26:
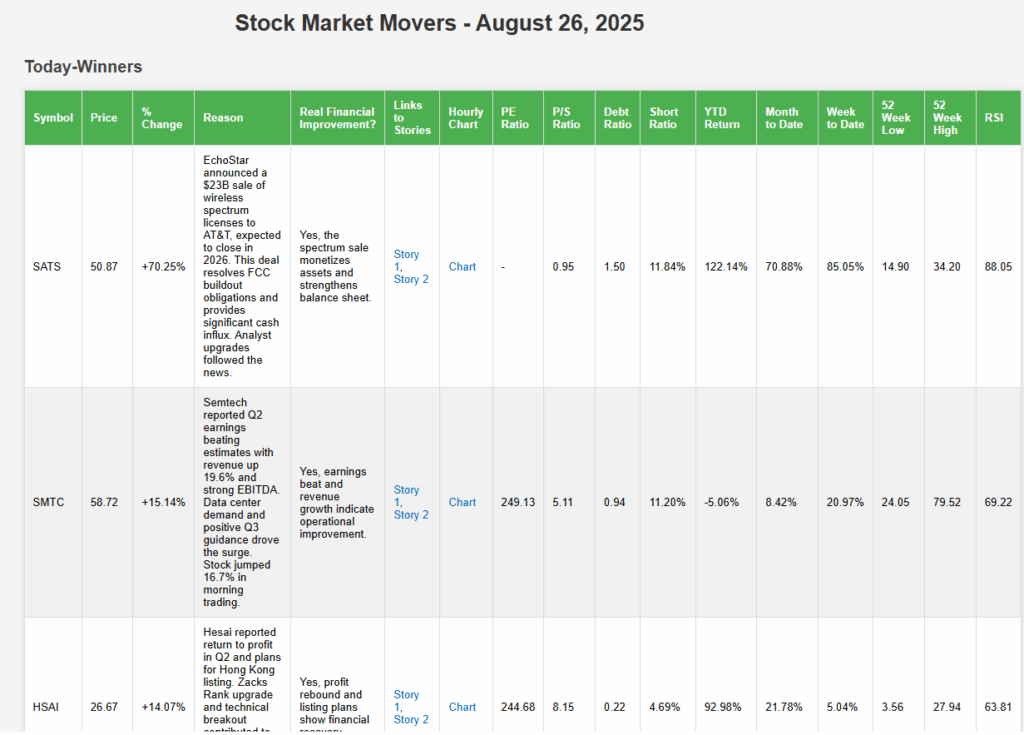
Snapshot of ChatGPT response to the Prompt FOR 08/28:

Evaluating LLMs : Radiology – Analysis of a PDF File of ECG from a cardiac stress test and interpreting anomalies
Prompt:
Upload a PDF file containing the ECG readings during a cardiac stress test with graphical measurements. Ask LLM to describe the contents of the file. Ask LLM to explain the anomalies found in the ECG readings with medical research references and interpret these anomalies to explain underlying medical problems with these cardiac measurements.
Youtube link: to be updated
Testing date 07/14/25 Category PDF-Med chart Reference: GC-PDMed-149255
Top Performers:(Score from 1-10)
Deepseek 9, Minimax 6.5
Catching up:
Qwen 5, Copilot 5, Mistral 5, Grok 4, Ernie 4, Kimi 4
Laggards:
Gemini 3, Manus 3, Claude 1
Not reading PDF:
ChatGPT 0, Perplexity 0, Meta AI 0
Test Links:
chat.deepseek.com chatgpt.com gemini.google.com claude.ai grok.com meta.ai perplexity.ai copilot.microsoft.com chat.qwenlm.ai chat.minimax.io chat.mistral.ai ernie.baidu.com kimi.com manus.im
Top performer in this test, Deepseek, is accurately able to identify that the PDF file contains Bruce Protocol tread mill test with different stages and can read the charts that show measurements from 12 different probes connected across the heart and chest area. Deepseek is able to correctly identify the anomalies found in the report. The findings from Deepseek match the analysis made by an experienced cardiologist previously from this ECG report. Deepseek correctly identifies presence of myocardial ischemia from the ECG measurements. By further focusing on measurements from a specific probe, Deepseek is correctly able to comment that partial blockage is present in left anterior descending artery. Medical references are provided by Deepseek for the interpretation. Further questions related to controlling cholesterol and hypertension are answered with detail. Replying to a question on how to reduce plaque build up in arteries, Deepseek recommended life style changes, diet and medication options. The key value in this analysis is the ability to correctly interpret the ECG charts and identify the anomalies from the test and provided a focused root cause. No other other LLM came close to the quality of this report.
Minimax also performed reasonably well, However, it over emphasized the severity of the anomalies found in the test and linked it to both ischemia as well as to Wolf-Parkinson-White syndrome which is incorrect. Due to its more alarming results and partially incorrect analysis, the LLM scored less points due to skewing of results.
The other LLMs Qwen, Copilot and Mistral did ok but were not as detailed in analysis as Deepseek or Minimax.
Grok, Gemini and others were restricted in their interpretation due to probable limitations on analyzing medical records, perhaps due to liability concerns. However, too much caution in providing answers to client inquiries makes these LLMs less useful as a go to AI tool.
Some LLMs like ChatGPT were not able to read the PDF files. I am assuming that ChatGPT can read pdfs, but its capability is not fully or publicly released at this point. As a tool, since this does not meet our usability function, these LLMs did not score any points in our test.
Details of the complete test are available on request.
Youtube link TBD
Snapshot of 11 page PDF file Prompt of ECG readings

Deepseek’s snapshot of ECG interpretation

Evaluating LLMs : Palmistry – Analysis of hand scans based on scientific and classical knowledge of Palmistry
Prompt:
Upload snapshots of full hand scans to the LLM. Give a detailed analysis of the full hand scan uploaded by using deep and advanced knowledge of palmistry from scientific, western, chinease, indian, arab and other ancient interpretations. Based on detailed analysis from palmistry, also explain the negative characteristics visible in theses hand prints.
Youtube link: to be updated
Testing date 07/25/25 Category PDF-Snapshot Reference: GC-SnapPM-11234591
Top Performers: (Score from 1-10)
Grok 7.5, ChatGPT 7.5
Catching up:
Gemini 6.5, Minimax 6.5, Qwen 6, Copilot 6, Kimi 6
Ernie 5, Perplexity 5, Mistral 5, Manus 5
Laggards:
Claude 3, Meta 3
Not reading Hand Scans:
Deepseek 0
Test Links:
chat.deepseek.com chatgpt.com gemini.google.com claude.ai grok.com meta.ai perplexity.ai copilot.microsoft.com chat.qwenlm.ai chat.minimax.io chat.mistral.ai ernie.baidu.com kimi.com manus.im
Both the top performers Grok and ChatGPT easily understand the hand prints and are able to provide a detailed and equally convincing analysis of the hand scans. Both right and left hand scans were uploaded.
Grok provided a general analysis of the hand structure, fingers, mounts, minor lines and markings on the hand. Grok also provided negative characteristics based on its interpretation of palmistry. Generally, the AI is programmed to filter out negative responses, so it was relevant to specifically ask for negative qualities in the prompt in order to get a positive and negative traits feedback from the LLM. The responses provided were compared with feedback from the owner of the handprint and multiple observations made by the LLMs were found to be quite accurate. The value of the LLM is most when the response is accurate for the input provided. So validation of results is necessary in these tests.
ChatGPT performed in a similar way, although its answer were more precise. However, the level of accuracy was quite similar to what was observed with Grok or better. ChatGPT response included hand shape, type, finger lengths, mount analysis, palm lines analysis including heart, head, life, fate, sun and mercury lines. ChatGPT also provided potential negative personality traits, scientific palmistry observations and multicultural analysis.
In both cases of Grok and ChatGPT, when asked to provide the same report in a pdf format, the output was almost half of what was provided in the direct chat mode. This suggests that further filters are applied when content is provided in a downloadable pdf format.
Gemini and Minimax also performed reasonably well followed by other LLMs.
Deepseek for some unknown reason is not able to provide any feedback saying it cannot read any text from the handprint provided. The cause for this limitation is not clear since several other Chinese LLMs are able to provide hand scan analysis.
Business case: Overall, developing an AI agent that does hand scan analysis using palmistry by employing LLMs can be built into a standalone app or integrated as a feature into a social media platform.
Details of the complete test are available on request.
Youtube link TBD
Sample input file for Hand scan used in Palmistry test

Grok’s interpretation of hand scan based on Palmistry


Evaluating LLMs : Code generation
Prompt:
Plot the 20 most populated cities in the world. I will be using Python on Google Colabs for this. Label on each city marker has different color codes and shows the name of the city on the map and population. Adjust the population rounded off to million below the name of the city on the map. Provide the complete code.
Youtube link https://youtu.be/G2KtzsIsg4Y
Testing date 02/26/25 Category Code Gen Reference: GC-CGen-160226
Top Performers:(Score from 1-10)
Deepseek 9, Grok 8.5, ChatGPT 7.5
Catching up:
Claude 7, Copilot 7, Mistral 7
Laggards:
Gemini 3, Meta 3, Perplexity 3, Qwen 3, Minimax 3
Test Links:
chat.deepseek.com chatgpt.com gemini.google.com claude.ai grok.com meta.ai perplexity.ai copilot.microsoft.com chat.qwenlm.ai chat.minimax.io chat.mistral.ai
Deepseek takes some time to process and “think”. Also looks like there is a lot of load on Deepseek, so sometimes the server is busy. However, overall, the performance for this Prompt was quite good and reproducible.
Grok is quite fast and looks like it has lot of compute power and is thinking similar to Deepseek but appears to converge much faster for the Prompt response. Scored slightly less since the labelling was better on Deepseek map.
ChatGPT also performed well, however, one of its two codes worked and in repeat testing offline provided one code which did not work.
Claude did not perform in the first test but provided a very good response when tested offline for the same prompt.
Microsoft Copilot provided the map but labels were only blue. Mistral provided a map but used orange, blue and red and did not allocate distinct colors for each city. Performance was the same in repeat offline tests.
Puzzled to see the poor performance of Google Gemini for which the generated code did not work on its own Colabs platform to create the map. Code did not work for Meta, Perplexity, Qwen, Minimax also. The tests were repeated for this Prompt with the failure were reproducible.
Details of the test are available in the below Youtube video and on request.
Youtube link https://youtu.be/G2KtzsIsg4Y
Map Results for the Prompt
DEEPSEEK

GROK

ChatGPT

CLAUDE

COPILOT MICROSOFT

MISTRAL
